Python的垃圾回收机制
我们都知道计算机资源主要存储在两个地方。一个是 硬盘,一个是 内存 。在编写程序定义变量的过程,我们就会申请内存空间,使用完后就应该释放。否则可能会造成 内存溢出 。好在 Python 存在 垃圾回收机制 不用我们进行内存管理。
垃圾回收机制主要包括:
- 引用计数
- 标记清除
- 分代回收
引用计数
引用计数就是一个值被几个变量引用。
name = 'ma' # 18被age引用
nam2 = name # 18 被age、age2同时引用
# 此时 'ma' 的引用计数为2。
假如我们再执行del name 删除变量 name,name = 'a'改变name2的指向。那么ma引用计数变为 0。就会被内存回收。
提示
del name 不是删除 'ma',而是删除name和'ma'之间的绑定关系。
标记清除
首先我们要明白为什么需要标记清除机制。现在假设我们写了以下代码:
l1 = [1, 2, l2]
l2 = ['a', 'b', l1]
del l1
del l2
当我们执行两个 del 语句后。外部变量对两个列表的引用为 0 。但两个列表还在相互引用,引用计数不为 0 。这时候我们就无法访问到这两个列表,也没有办法将它从内存中清除,它们会一直占据着内存。这就是 内存泄漏 。
要想弄明白,标记清除的实现原理。我们需要了解 变量名 和 变量值 在内存中的存储关系。
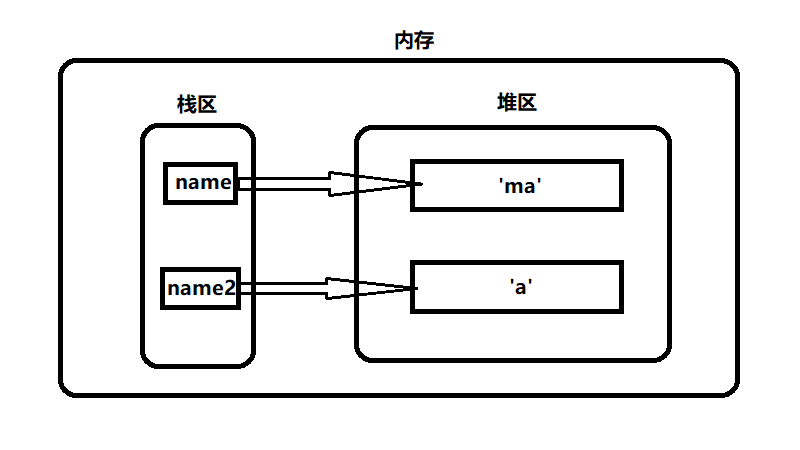
如图所示在内存中,变量名存储在 栈区 变量值存储在 堆区 。两者存在引用关系。所谓的标记清除就是 Python 扫描栈区,发现有通过栈区引用不到的值就会将它回收。
所以上面例子中,即使两个列表还在相互引用,引用计数不为 0 。但是在栈区内没有变量引用这两个列表,那么他们就会被回收。
分代回收
通过 引用计数 和 标记清除 已经可以回收所有垃圾。但是由于每次查看引用计数的时候会遍历扫描所有变量,效率比较低。所以就产生了 分代回收 。举个例子:
刚开学时,老师每个人都不认识。检查作业时一致同仁,每个人都三天检查一次。但随着时间的增长,对于表现好的同学可能一周检查一次,表现不好的一天检查一次。又过了一段时间,可能表现更好的同学一个月检查一次,表现更不好的再增加检查频率。分代回收机制 也是如此,对不同的变量进行不同频率的扫描,以此来增加扫描效率。
至此,垃圾回收机制就讲完了。总结来说,垃圾回收机制通过 引用计数 来扫描回收垃圾,通过 标记清除 来回收引用计数回收不了的垃圾,通过 分代回收 来提高效率。